
こんにちは、六本木アナリティクスエンジニアのTaku(@aelabdata )です。

データはたくさんあるのに、分析がなかなか進まない

レポートによって数値が違うけど、このデータ、本当に信頼できる?
これらの課題の多くは、単にツールを導入するだけでは解決できません。その鍵を握るのが、「データモデリング設計」と、それをdbt(data build tool)で実装する「多層アーキテクチャ」です。
私たちが目指すべきは、誰もが信頼できる「Single Source of Truth(唯一の信頼できる情報源)」を確立すること。そのためには、生データから分析可能な形へとデータを整理・加工する体系的なプロセスが不可欠です。
今回は、私が現在、既存のデータ基盤をより「使えるデータ分析基盤」にするためにビジネスケースからのリファクタリングを進める中で実践したdbtを使ったデータモデリングのレイヤー設計をご紹介します。
データモデリングにおける「多層アーキテクチャ」の必要性
データモデリングにおける多層アーキテクチャとは、生データが最終的な分析データになるまでのプロセスを、いくつかの明確な「層(レイヤー)」に分けて管理する考え方です。各層が特定の目的と役割を持つことで、以下のメリットが生まれます。
- 信頼性の向上: 各層でデータ品質チェックや変換ルールを適用し、エラーを早期に発見・対処できます。
- 保守性の向上: 変更が発生した場合でも、影響範囲を限定しやすくなり、改修が容易になります。特に既存のデータモデルをリファクタリングする際には、影響範囲を絞り込みやすくなります。
- 再利用性の向上: 各層で共通のデータモデルや中間データを定義することで、複数の分析やレポートで再利用できます。
- パフォーマンスの最適化: 分析の目的に合わせてデータを集約・整形することで、BIツールのクエリ速度を向上させます。
- 分業の明確化: データエンジニアとアナリティクスエンジニアの間で、どこまでがデータエンジニアの責任で、どこからがアナリティクスエンジニアの責任かを明確にできます。
そして、この多層アーキテクチャを効率的かつ体系的に構築するために、dbtが非常に強力なツールとなります。dbtはSQLとソフトウェアエンジニアリングのベストプラクティスを組み合わせることで、データ変換をコード化し、テスト、バージョン管理、ドキュメント化を容易にします。
dbtで構築する多層アーキテクチャ:5つのレイヤー設計案
それでは、具体的な5つのレイヤー設計案を見ていきましょう。この設計は、スタースキーマモデルを前提に、dbt best practicesと一般的なデータウェアハウスの3層構造(Datalake, DWH, Datamart)をベースに、柔軟性と拡張性を持たせたものです。
| レイヤー名 | レイヤー種別 | 3層構造対応 | 目的・内容 | テーブル名プレフィックス |
|---|---|---|---|---|
| ① RAW層 (Source層) | dbt best practices | Datalake | データソースをそのまま表現。加工は行わず、信頼できるデータ取り込みの「入口」。 | – |
| ② STAGING層 | dbt best practices | DWH | 型変換・命名統一・軽微な整形(カラム揃え、NULL値対応など)。生データの整理。 | stg_ |
| ③ INTERMEDIATE層 | dbt best practices | DWH | 複数のテーブルの結合(Join)や複雑な集計など、中間的な整形を行う。 | int_ |
| ④ MART層 (ビジネス) | dbt best practices | DWH | スター・スキーマ(Fact/Dim)モデルの集約。ビジネスユーザー向けの最終データ。 | dim_ / fact_ |
| ⑤ Exposure層 | 独自層 | Datamart | マートレイヤーのデータから、特定のビジネス要件に基づいて出力したデータ。BIツール連携特化やReverse ETL用など。 | agg_ / exp_ |
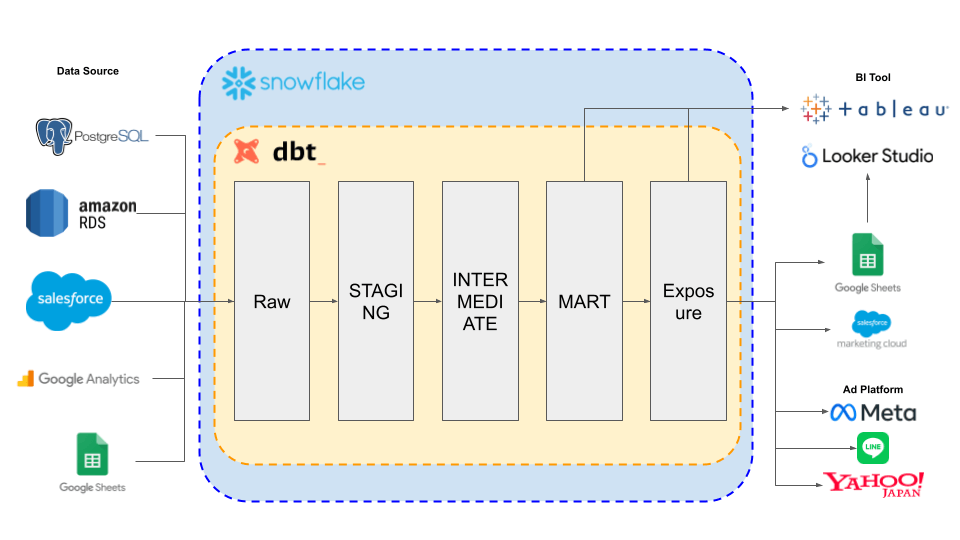
各レイヤーについて、dbtでの実装イメージを交えながら詳しく見ていきましょう。
① RAW層 (Source層)
- 目的・内容: 外部データソース(SaaS、DB、CSVなど)からDWHにロードされた、手を加えていない生データそのものを格納します。信頼できるデータの入り口であり、データの原典となります。この層のデータは極力変更せず、問題が発生した場合の遡りや再処理の起点となります。既存のデータ基盤では、この層のデータがきちんと保持されているかを確認することがリファクタリングの第一歩です。
- dbtでの実装: dbtでは、
sources.ymlファイルで外部テーブルとして定義し、データソースを明確に宣言します。これにより、ダウンストリームのモデルがどのソースに依存しているかを可視化できます。
② STAGING層
- 目的・内容: RAW層の生データに対して、軽微な整形やクリーンアップを行います。具体的には、
- データ型の変換(例:文字列から日付型へ)
- カラム名の統一(例:
user_id、customer_idなど) - NULL値や欠損値の基本的な処理
- 不要なカラムの削除
- プライマリキーの定義や重複排除
この層は、次のINTERMEDIATE層やMART層で加工しやすくするための「準備段階」と位置づけられます。
- dbtでの実装:
models/stg/ディレクトリ内に、各ソーステーブルに対応するビューまたはテーブルを作成します。命名規則はstg_[データソース名]_[テーブル名]のように統一すると管理しやすくなります。
③ INTERMEDIATE層
- 目的・内容: STAGING層のデータを組み合わせて、より複雑な加工や集計を行います。具体的には、
- 複数のStagingテーブルの結合(例:注文データと顧客データの結合)
- 複雑なビジネスロジックに基づく計算(例:LTV算出の中間ステップ)
- 時系列データのウィンドウ関数による集計
この層は、共通の中間ロジックや集計を担うことで再利用性を高める役割があります。
- dbtでの実装:
models/int/ディレクトリ内にモデルを作成します。int_[関連エンティティ名]_[処理内容]のような命名規則が考えられます。この層のモデルは、他のint_モデルやstg_モデルに依存します。
④ MART層 (ビジネス)
- 目的・内容: 分析を目的とした、スター・スキーマ(FactテーブルとDimensionテーブル) を構築します。
- Factテーブル: 売上、イベント、注文など、ビジネスの事象(トランザクション)を記録するテーブル。
- Dimensionテーブル: 顧客、商品、日付など、Factテーブルの文脈を説明する属性情報を持つテーブル。
- dbtでの実装:
models/mart/ディレクトリ内にdim_[エンティティ名](Dimensionテーブル)とfact_[事象名](Factテーブル)のモデルを作成します。この層のモデルは、主にint_モデルに依存します。
⑤ Exposure層
- 目的・内容: MART層のデータをさらに加工し、特定のビジネスアプリケーションやツールへの出力に特化したデータセットを作成します。これは、BIツール連携の最適化や、Reverse ETLの最終出力層として機能します。
- 集計されたテーブル:
agg_として、特定のBIダッシュボード向けに最適化された集計データ。 - 非集計のテーブル:
exp_として、CRMやMAツールへのインポート用に整形されたデータ。
この層は、柔軟性を持たせるための独自層であり、必ずしも全てのプロジェクトで必要とされるわけではありませんが、複雑なデータ活用のニーズに応えるために有効です。
- 集計されたテーブル:
- dbtでの実装:
models/exp/ディレクトリ内にモデルを作成します。agg_[レポート名]やexp_[連携先システム名]のような命名規則が考えられます。この層のモデルは、主にdim_やfact_モデルに依存します。
おわりに
今回ご紹介したdbtを活用した5層構造のデータモデリング設計は、データの流れを明確にし、各層の役割を限定することで、以下のメリットをもたらします。
- データ品質の向上と一貫性の確保
- モデルの保守性と拡張性の向上
- ビジネス要件への迅速な対応
- BIツールのパフォーマンス最適化
- 役割分担の明確化と協業の促進
今後も、より「使えるデータ分析基盤」にするために、Exposure層をSemantic Layerを導入したり、Data Vaultデータモデリングを導入したりを検討しています。データ分析基盤は一度作ったら終わりではなく、ビジネスの変化に合わせて常に改善していきましょう。
この記事が役に立ったと感じたら、ぜひX(@aelabdata)をフォローください!日々のアナリティクスエンジニアとしての学びや、記事の更新情報を発信しています。

