
こんにちは、六本木アナリティクスエンジニアのTaku(@aelabdata )です。
dbt入門の第7回です。前回は、データウェアハウス(DuckDB)にロードした生データを、sources.ymlファイルを定義することで、dbtがSourceとして認識できるようになりました。
 Sourceを定義しよう:dbt-osmosisで自動生成
Sourceを定義しよう:dbt-osmosisで自動生成
今回は、これらのSourceをクリーンナップし、基本的な変換を施し、データ変換パイプラインの次の層であるステージングモデル(staging models)を作成しましょう。
Stagingモデルとは
Stagingモデルは、第5回で解説したdbtが推奨するプロジェクト3層構造の最初のステップです。
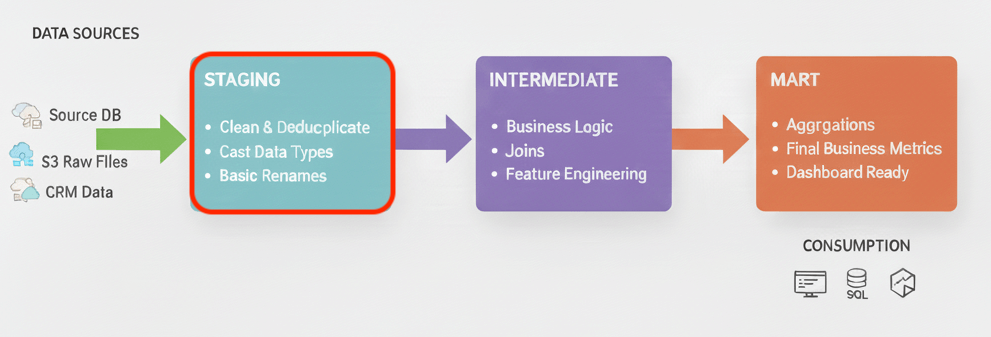
第5回より再掲します。詳細はリンク先をご覧ください。
 成功するdbtプロジェクトの秘訣:3層構造とディメンショナルモデリング
成功するdbtプロジェクトの秘訣:3層構造とディメンショナルモデリング
ステージング層は、ソースデータに最小限の処理を施し、プロジェクト全体の信頼できる基盤を構築します。
- 目的: ソースシステムの癖を抽象化し、プロジェクトの他の部分が信頼して利用できる、標準化されたデータを作成します。
- 処理の原則: 原子的な構成要素(Atoms)を作成する層であり、結合(JOIN)は行いません。ソーステーブルと1対1の関係を保ちます。
- 具体的な変換(最小限):
- カラム名の変更(例:
id→customer_idなど、プロジェクトの命名規則に統一) - データ型のキャスト(型変換)
- 基本的なデータのクリーンアップ(NULL値の標準化など)
- カラム名の変更(例:
dbtプロジェクトの可読性とメンテナンス性を高めるために、命名規則とフォルダ構成の規約を守ることが推奨されます。Stagingモデルは、以下のルールに従って配置します。
- フォルダ構成:
models/staging/ディレクトリの下に、データソースごとにサブディレクトリを作成します。models/staging/jaffle_shop/
- ファイル命名規則: ファイル名は
stg_<ソース名>__<テーブル名>.sqlという形式にします。models/staging/jaffle_shop/stg_jaffle_shop__customers.sqlmodels/staging/jaffle_shop/stg_jaffle_shop__orders.sql
この厳格な命名規則は一見冗長に思えるかもしれませんが、大規模なプロジェクトでは絶大な効果を発揮します。どのStagingモデルがどのソースから来ているかが一目で分かり、命名の衝突を防ぐことができるのです。
Stagingモデルの役割を再確認した今、次はPower User for dbt (Altimate Inc.)を使ってStagingモデルの自動生成しましょう。
Power User for dbtでStagingモデルを自動生成する手順
ここからは、これまでの理論と準備を実践に移します。Power User dbtの強力な自動生成機能を使い、手作業をいかに迅速かつ正確なプロセスに変えられるかを、ステップ・バイ・ステップで解説します。この手順に従うことで、数分とかからずにプロジェクトの基盤となるStagingモデルの雛形を完成させることができます。
「Generate model」に関する設定を2ヵ所変更します。
まずは、生成されるSQLモデルのファイル名を指定します。Dbt: File Name Template Generate Modelから、{prefix}_{sourceName}__{tableName}を選択します。
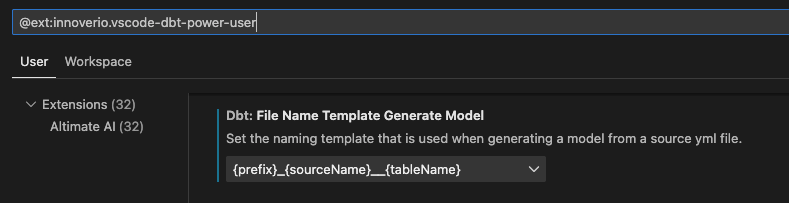
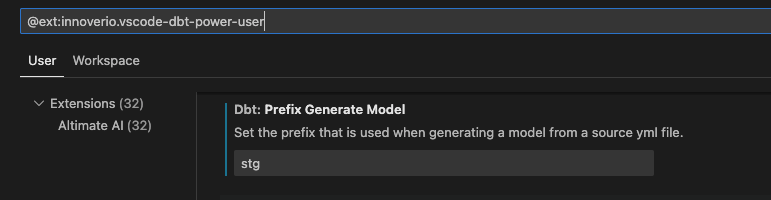
次に、プレフィックス(Prefix)をを指定します。Dbt: Prefix Generate Modelをstgに変更します。
まず、前回準備した_jaffle_shop__sources.ymlファイルを開きます。
jaffle_shopソース配下にあるraw_customersテーブルの上にある「Generate model」をクリックします。
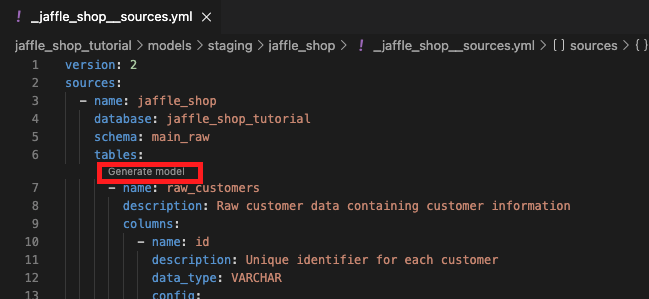
「Generate model」を選択すると、dbt Power Userは即座に新しいSQLファイルstg_jaffle_shop__raw_customers.sqlを、_jaffle_shop__sources.yml.yml
with source as (
select * from {{ source('jaffle_shop', 'raw_customers') }}
),
renamed as (
select
{{ adapter.quote("id") }},
{{ adapter.quote("name") }}
from source
)
select * from renamed
生成されたモデルが構文 {{ adapter.quote(column_name)}} で表示されるのは、拡張機能は様々なアダプタをサポートしているためです。これがすべてのアダプタで動作することを保証しています。Copilotなどで修正しましょう。
Stagingモデルのベストプラクティスに沿って修正を加えることが、高品質なデータモデリングの鍵となります。Staging層は、カラムのエイリアシング、データ型のキャスト、基本的なクレンジングといった基礎的な変換をします。
ここでは、idとnameをビジネスコンテキストで意味の通じるcustoemr_idとcumstmer_nameにリネームします。
with source as (
select * from {{ source('jaffle_shop', 'raw_customers') }}
),
renamed as (
select
id as customer_id,
name as customer_name
from source
)
select * from renamed
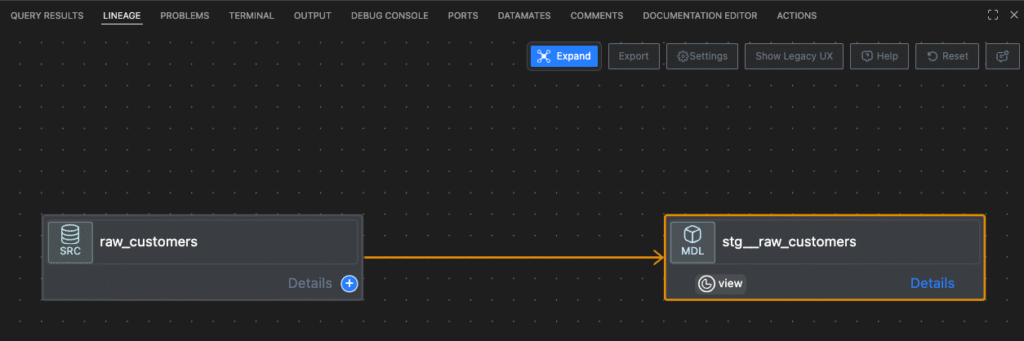
{{ source('jaffle_shop', 'raw_customers') }}というdbtの構文が、依存関係を定義する上で重要です。LINEAGEをみると、raw_customersからstg_jaffle_shop__raw_customersが作成されていることが確認できます。
raw_ordersテーブルとraw_itemsテーブルについても、Stagingモデルを作成しましょう。
with source as (
select * from {{ source('jaffle_shop', 'raw_orders') }}
),
renamed as (
select
id as order_id,
customer as customer_id,
ordered_at,
store_id,
subtotal,
tax_paid,
order_total
from source
)
select * from renamed
with source as (
select * from {{ source('jaffle_shop', 'raw_items') }}
),
renamed as (
select
id as item_id,
order_id,
sku
from source
)
select * from renamed
dbt buildをしてStagingモデルをDuckDBに作成しましょう。
dbt buildCompleted successfullyというメッセージが表示されたら、成功です。お疲れ様でした。
まとめと次のステップ
この記事では、dbtプロジェクトにおけるStaging層の重要性を理解し、Power User for dbtを使って効率的に作成する方法を学びました。
- Staging層の役割: データモデリングの基盤として、ソースデータを整理し、再利用可能なコンポーネントを作成する重要性を再確認しました。この層で基本的な変換を一元管理することが、プロジェクト全体の保守性と信頼性を高めます。
- Power User for dbtによる自動化: モデル作成の自動化が、開発速度の向上、タイプミスの削減、命名規則の一貫性維持にどれほど貢献するかを学びました。これは単なる時間節約ではなく、データ品質とチームの生産性を向上させるための戦略的なプラクティスです。
- dbt開発のベストプラクティス:
source()関数の使用や、一貫した命名規則とフォルダ構造の維持といった、dbtプロジェクトをスケールさせるための基本的な習慣の価値を強調しました。これらの規律が、複雑なプロジェクトでも見通しの良さを保つ秘訣です。
Stagingモデルという強固な土台ができた今、次はいよいよビジネス価値を生み出すMartsモデルの構築へと進む番です。次回は、今回作成したStagingモデルを利用して、Martsモデルを作成しましょう。
本講座で扱うデータ変換処理は比較的シンプルであり、ステージングモデル同士を直接結合してもSQLが複雑になりすぎることはありません。そのため、学習のしやすさと構成のシンプルさを優先し、今回はIntermediate層を省略して、Staging層から直接Marts層を作成するアプローチを採用します。
