
こんにちは、六本木アナリティクスエンジニアのTaku(@aelabdata )です。
dbt入門の第8回です。前回は、Power User for dbtを使って効率的にStagingモデルを実装しました。
今回は、Stagingモデルを組み合わせ、Martsモデルを構築していきましょう。
Martsモデルとは
Martsモデルは、第5回で解説したdbtが推奨するプロジェクト3層構造の最後のステップです。
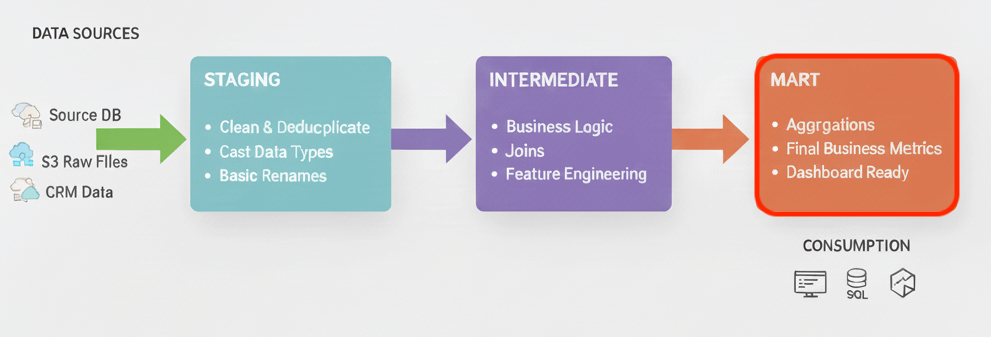
Martsモデルの役割を、再確認しましょう。詳細はリンク先から第5回をご覧ください。
 成功するdbtプロジェクトの秘訣:3層構造とディメンショナルモデリング
成功するdbtプロジェクトの秘訣:3層構造とディメンショナルモデリング
Mart層は、中間層で整備されたデータを組み合わせ、ビジネス部門が直接利用するための最終的なデータセットを構築します。
- 目的:
- ビジネス部門が直接利用できる、最終的なデータマートを作成します。
- BIツール(Tableau, Lookerなど)からの参照に最適化されたデータを提供します。
- 処理の原則:
- ディメンショナルモデリングを実践します。
- 中間モデルを組み合わせて、ビジネスで定義されたエンティティ(顧客、注文など)に関する「広く、リッチなビジョン」を持つモデルを構築します。
- 特徴:
- 利用者の信頼性: ビジネスロジックが最終的に確定し、品質が保証されたデータ資産となります。
- 高い分析効率: スター・スキーマにより、BIツールでのクエリパフォーマンスと操作性が向上します。
それでは、実際にMartsモデルを構築していきましょう。
実践1:顧客ごとの指標を持つDimensionモデルの作成
最初のステップとして、顧客ディメンションdim_customersを作成します。
CTE (Common Table Expressions) を用いて、処理のステップを段階的に記述していきます。この構造は、SQLの可読性とメンテナンス性を大幅に向上させるためのベストプラクティスです。
models/marts/core/dim_customers.sqlのSQLファイルを作成します。
- 必要なモデルの読み込み: 最初のステップとして、
stg_jaffle_shop__raw_customers(顧客ステージングモデル)とstg_jaffle_shop__raw_orders(注文ステージングモデル)を、それぞれref()関数を使ってCTEとして定義します。これにより、どのモデルに依存しているかが明確になります。 - 顧客ごとの指標集計: 次に、
orderscustomer_idでGROUP BYし、min(order_date)でfirst_order_date(最初の注文日)、max(order_date)でmost_recent_order_date(最新の注文日)、count(order_id)でnumber_of_orders(総注文回数)、sum(order_total)でtotal_order_amount(総注文金額)を集計します。この集計結果をcustomer_ordersという名前のCTEとして定義します。 - 最終的な結合: 最後に、
customersCTEを主軸(左側)とし、customer_ordersCTEをcustomer_idをキーにしてLEFT JOINします。ここでLEFT JOINを使うことが重要です。これにより、まだ一度も注文していない顧客情報も失われることなく、最終的なモデルに残すことができます。
上記のロジックを実装した完全なSQLコードは以下の通りです。これをdim_customers.sqlファイルにコピー&ペーストしてください。
with customers as(
select * from {{ ref('stg_jaffle_shop__raw_customers') }}
),
orders as(
select * from {{ ref('stg_jaffle_shop__raw_orders') }}
),
customer_orders as (
select
customer_id,
min(ordered_at) as first_order_date,
max(ordered_at) as most_recent_order_date,
count(ordered_at) as number_of_orders,
sum(order_total) as total_oreder_amount
from orders
group by customer_id
),
final as (
select
customers.customer_id,
customers.customer_name,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
customer_oreders.total_order_amount
from customers
left join customer_orders
on customers.customer_id = customer_orders.customer_id
)
select * from finalこれで、顧客ディメンションモデルが完成しました。次は、注文のファクトモデルを作成しましょう。
実践2:注文イベントを記録するFactモデルの作成
ビジネス上の「出来事」を定義するfct_ordersモデルを作成します。
models/marts/fct_orders.sqlのSQLファイルを作成します。
- 必要なモデルの読み込み: 最初のステップとして、
stg_jaffle_shop__raw_orders(注文ステージングモデル)とstg_jaffle_shop__raw_items(注文商品ステージングモデル)を、それぞれref()関数を使ってCTEとして定義します。これにより、どのモデルに依存しているかが明確になります。 - 顧客ごとの指標集計: 次に、
itemsorder_idでGROUP BYし、count(item_id)でitem_count(注文商品数)を集計します。この集計結果をitems_groupedという名前のCTEとして定義します。 - 最終的な結合: 最後に、
ordersCTEを主軸(左側)とし、item_groupedCTEをorder_idをキーにしてLEFT JOINします。
上記のロジックを実装した完全なSQLコードは以下の通りです。これをfct_orders.sqlファイルにコピー&ペーストしてください。
with orders as (
select * from {{ ref('stg_jaffle_shop__raw_orders') }}
),
items as (
select * from {{ ref('stg_jaffle_shop__raw_items') }}
),
items_grouped as (
select
order_id,
count(item_id) as item_count
from items
group by order_id
)
select
orders.order_id,
orders.customer_id,
orders.ordered_at,
orders.store_id,
orders.subtotal,
orders.tax_paid,
orders.order_total,
items_grouped.item_count
from orders
left join items_grouped
on orders.order_id = items_grouped.order_idこれで、分析にすぐに使える注文ファクトモデルのSQLが完成しました。次のステップでは、実行して結果を確認しましょう。
実行と結果の確認
最終ステップとして、dbtコマンドを実行してデータパイプラインを動かします。
このステップの素晴らしい点は、私たちがモデルの実行順序を気にする必要がないことです。dbtがref()関数で定義されたモデル間の依存関係(リネージ)を自動的に解析し、正しい順序でビルドを実行してくれます。この手動での実行順序管理からの解放は、dbtがもたらす大きなメリットの一つです。
ターミナルを開き、dbtプロジェクトのルートディレクトリで以下のコマンドを実行してください。
dbt build実際のプロジェクトでは、モデルの実行とテストは常にセットで考えます。dbt buildを使うことで、「実行は成功したが、テストが失敗した」といった中途半端な状態を防ぎ、パイプラインの信頼性を担保できます。もちろん、dbt runコマンドを使ってモデルの実行だけを行うことも可能です。
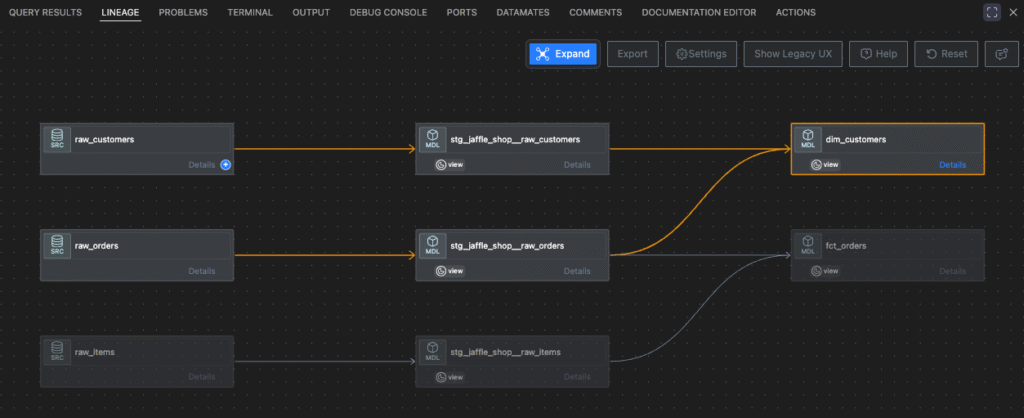
dbt buildコマンドを実行すると、ターミナルに実行ログが表示されます。そのログに注目してください。dbtがまずStaging層のモデル(stg_...)をビルドし、次にそれを参照しているfct_ordersとdim_customersをビルドするという、正しい順序で処理を進めていることが確認できるはずです。これは、dbtが内部でDAG(有向非巡回グラフ)を構築し、依存関係を解決しているおかげです。
LINEAGEタブからも確認してみましょう。
ビルドが正常に完了したら、dim_customersテーブルに顧客ごとの集計指標が正しく付与されているかを確認しましょう。データウェアハウスに直接クエリを投げる代わりに、dbtの便利なshowコマンドを使えば、モデルの結果をターミナル上で素早くプレビューできます。
dbt show --select dim_customersこのコマンドを実行して、結果が出力されたら、データ変換が成功したことを視覚的に確認できます。
これで、すべてのモデルがデータウェアハウス上にテーブルとして正しく構築され、データ変換が成功したことが確認できました。
まとめと次のステップ
この記事では、Martsの役割を再確認し、Marts層にディメンショナルモデルを実装しました。
- Marts層の役割とディメンショナルモデリングの基本
- Factモデル(
fct_orders)と、Dimensionモデル(dim_customers)をdbtで実装 - dbtの依存関係解決機能を活用して、データパイプライン全体を自動で実行
次回は、作成したStagingモデル、Martモデルを、データウェアハウス上に、どのように実体化するかという、Materialization(マテリアライゼーション)についてです。

