
こんにちは、六本木アナリティクスエンジニアのTaku(@aelabdata )です。
dbt入門の第3回です。前回は、データモデリング環境構築の準備編で、dbt coreとVS codeとDuckDBのメリットと環境構築に必要な前提を解説しました。
 dbt coreとVS CodeとDuckDBで始めるデータモデリング環境構築ガイド(準備編)
dbt coreとVS CodeとDuckDBで始めるデータモデリング環境構築ガイド(準備編)
今回は、dbt Core、Visual Studio Code (VS Code)、そしてDuckDBを用いて、あなたのローカルマシン上にモダンなデータモデリング環境をゼロから構築するための「実践編」ガイドです。前回の理論中心の記事とは異なり、今回は実際に手を動かしながら、具体的な手順を一つひとつ追っていくハンズオン形式で進めていきます。
dbt Cloudも非常に優れたSaaSプラットフォームですが、コストやIDEの柔軟性の観点からローカル環境を選択するメリットは少なくありません。特に、使い慣れたVS Codeの強力な編集機能や拡張性を活用できる点は、日々の開発効率を大きく向上させるでしょう。
この記事を読み終える頃には、あなたは以下のスキルを習得し、一人でdbtプロジェクトの初期設定を完遂できるようになります。
- GitHubでのプロジェクト管理
- Python仮想環境の構築とdbtのインストール
- dbtプロジェクトの初期化
- DuckDBへの接続設定
- 最初のdbtモデルの実行と結果確認
まずは、すべてのコードを管理する基盤となるGitHubリポジトリの準備から始めましょう。
Git/GitHubによるバージョン管理の準備
データモデリングのコードをGitでバージョン管理することは、開発フローにおける基礎です。これにより、コードの変更履歴を正確に追跡し、問題が発生した際には特定の時点にコードを戻すことができます。
また、チームでの共同作業を円滑にし、誰が・いつ・なぜ変更を加えたのかを明確にすることで、プロジェクトの透明性と再現性を確保します。これは、個人開発かチーム開発かを問わず、不可欠なベストプラクティスと言えます。
- GitHubにログインし、新しいリポジトリを作成します。
- リポジトリ名として
dbt-tutorial-duckdbのような分かりやすい名前を入力します。 - リポジトリの表示設定は
Privateを推奨します。これにより、誤って認証情報などの機密情報を含んだコードを公開してしまうリスクを防ぎます。 Add READMEにチェックを入れることを推奨します。dbtプロジェクトのローカルでの初期設定(dbt initなど)を完了した後、作成したコードをGitHubにプッシュする際、リポジトリが完全に空であると、いくつか追加の手順が必要になります。- その他の設定はデフォルトのままで「Create repository」ボタンをクリックします。
次に、作成したGitHubリポジトリをローカルマシンにコピー(クローン)し、VS Codeで開きます。
ターミナルを開き、git clone コマンドでリポジトリをクローンします。YOUR_USERNAMEの部分はご自身のGitHubユーザー名に置き換えてください。
# リポジトリをコピー
git clone https://github.com/YOUR_USERNAME/dbt-tutorial-duckdb.git
# コピーしたフォルダに移動
cd dbt-tutorial-duckdb
# VS Codeを起動
code .リポジトリの準備が整いました。次は、このプロジェクト専用のクリーンなPython環境を構築していきましょう。
Python仮想環境の構築とdbtのインストール
Pythonの仮想環境を利用することは、プロジェクトの独立性と再現性を保証するための鉄則です。
仮想環境を作成することで、プロジェクトごとに必要なライブラリ(依存関係)を完全に分離できます。これにより、他のプロジェクトやシステム全体のPython環境と干渉することなく、バージョン競合のような厄介な問題を未然に防ぎ、誰でも同じ環境を再現できる状態を保証します。
VS Codeの統合ターミナル(表示 > ターミナル)を開き、以下のコマンドを実行して仮想環境を作成し、有効化します。
python3 -m venv venv
source venv/bin/activateコマンド実行後、ターミナルのプロンプトの先頭に (venv) と表示されれば、仮想環境が正しく有効化されています。
有効化された仮想環境内で、dbt Core本体とDuckDBに接続するためのアダプタをpipコマンドでインストールします。
pip install dbt-core dbt-duckdbインストールが成功したかを確認するために、バージョン確認コマンドを実行しましょう。
dbt --versionバージョン情報が表示されれば、インストールは成功です。
必要なツールがインストールできました。いよいよ、dbtプロジェクトを作成して、データモデリングの土台を築いていきましょう。
dbtプロジェクトの初期化
「dbtプロジェクト」とは、単なるSQLファイルの集まりではありません。それは、データモデル(.sql)、テスト(.yml)、ドキュメント、マクロ、シードデータなどを体系的に管理するための、明確なディレクトリ構造と設定ファイル(dbt_project.yml)で構成された作業単位です。dbt initコマンドは、このプロジェクトの骨格を自動的に生成してくれる非常に便利なコマンドです。
ターミナルで以下のコマンドを実行し、新しいdbtプロジェクトを作成します。
dbt init jaffle_shop_tutorialこのコマンドを実行すると、対話形式でデータベース接続に関する質問が表示される場合があります。duckdbの番号を入力してEnterキーを押します。

コマンドが完了すると、jaffle_shop_tutorialという名前のディレクトリが作成されます。中には、以下のような主要なフォルダとファイルが生成されています。
models/: データモデル(SELECT文を記述したSQLファイル)を格納する場所。seeds/: CSVファイルをデータベースにロードするためのシードファイルを格納する場所。tests/: データ品質をテストするためのカスタムテストを格納する場所。dbt_project.yml: プロジェクト全体の設定を管理する中心的なファイル。
プロジェクトの雛形ができました。しかし、このままではdbtはどのデータベースに接続すればよいか分かりません。次に、dbtにDuckDBの場所を教えるための接続設定ファイルを作成します。
DuckDBへの接続設定(profiles.ymlの作成)
profiles.ymlは、dbtがデータベースに接続するための認証情報や接続先情報を定義する極めて重要なファイルです。このファイルは、dbtプロジェクト本体とは分離された特定の場所(通常はホームディレクトリ配下の~/.dbt/)に配置します。これにより、パスワードなどの機密情報をGitリポジトリにコミットしてしまう事故を防ぎ、複数のdbtプロジェクトで接続情報を安全に再利用できます。
~/.dbt/ディレクトリにprofiles.ymlという名前のファイルを作成します。(~はユーザーのホームディレクトリを指します。このディレクトリ配下に .dbt フォルダを作成してください。このディレクトリが存在しない場合は、先に作成する必要があります。)
作成したprofiles.ymlという名前のファイルを作成し、以下の内容をコピー&ペーストします。
jaffle_shop_tutorial:
target: dev
outputs:
dev:
type: duckdb
path: 'jaffle_shop.duckdb'type: duckdb: dbtにDuckDBアダプタを使用するよう指示します。path: jaffle_shop.duckdb: 接続先のDuckDBデータベースファイルのパスを指定します。ここでは相対パスを指定しているため、dbtコマンドを実行したプロジェクトのルートディレクトリにjaffle_shop.duckdbというファイルが作成されます。
設定が正しいかを確認するために、dbtプロジェクトのディレクトリ内でdbt debugコマンドを実行します。
# jaffle_shop_tutorial ディレクトリに移動していることを確認
cd jaffle_shop_tutorial
dbt debugターミナルに出力された結果の中に、以下のようなメッセージが表示されれば接続は成功です。
...
Connection test: OK connection ok
...
All checks passed!無事にデータベースとの接続が確認できましたね!これで準備は万端です。早速、dbtの魔法を体験してみましょう。
最初のdbt runと結果の確認
dbt runは、dbtワークフローの中核をなす最も基本的なコマンドです。
このコマンドを実行すると、dbtはmodelsディレクトリ内のすべてのSQLファイルを読み込み、ref関数などに基づいてモデル間の依存関係を自動的に解決します。そして、正しい順序でデータベースに対してSQL(CREATE VIEWやCREATE TABLEなど)を実行し、データモデルを物理的なオブジェクトとして構築します。
プロジェクトディレクトリ内で、以下のコマンドを実行してください。
dbt runコマンドが成功すると、以下のような出力が表示されます。Completed successfullyというメッセージが成功の証です。
...
[OK created view model main.my_first_dbt_model]
[OK created view model main.my_second_dbt_model]
...
Finished running 2 view models in 0 hours 0 minutes and 0.50 seconds (0.50s).
Completed successfullydbt runによって、プロジェクトのルートディレクトリにjaffle_shop.duckdbというデータベースファイルが作成されたはずです。これがDuckDBの大きな特徴の一つです。サーバーも不要で、単一のデータベースファイルとしてすべてのデータとスキーマが管理されます。
この中身をDuckDBのCLI(コマンドラインインターフェース)を使って確認してみましょう。
新しいターミナルを開くか、現在のターミナルで以下のコマンドを実行してDuckDB CLIを起動します。
# jaffle_shop_tutorial ディレクトリに移動していることを確認
cd jaffle_shop_tutorial
duckdb jaffle_shop.duckdbDuckDBのプロンプト (D>) が表示されたら、以下のSQLクエリを実行して、dbtが作成したビュー(またはテーブル)が存在することを確認します。
# テーブル一覧を表示
D show tables;
# my_first_dbt_modelテーブルのデータを確認
D select * from my_first_dbt_model;
# DuckDBのCLI終了
D .quit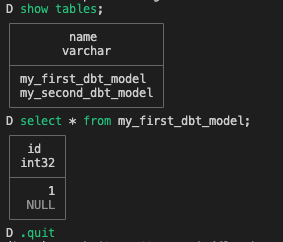
この確認作業を通して、あなたが書いた(この場合はサンプルですが)SQLが、dbtによって実際にデータベース内にオブジェクトを構築したことを実感できたはずです。
SQLファイルを実行し、データベースにテーブルを作成することができました。この成果を忘れないように、GitHubに記録しておきましょう。
変更内容のコミットとGitHubへのプッシュ
開発プロセスにおいて、一つのまとまった作業が完了したタイミングで「コミット」を作成することは、非常に重要な文化です。
これにより、プロジェクトの歴史が意味のある単位で記録されます。後から変更内容を追いやすくなるだけでなく、将来問題が発生した際に原因を特定し、特定のバージョンに戻すことが格段に容易になります。これは、個人開発でもチーム開発でも同様に価値のあるベストプラクティスです。
作業内容を記録するための新しいブランチを作成します。mainブランチに直接コミットするのではなく、機能ごとにブランチを切るのが一般的です。
git switch -c feat/initial-dbt-setupここまでの変更をステージングし、意味のあるコミットメッセージを付けてコミットし、GitHubのリモートリポジトリにプッシュします。
# すべての変更をステージングエリアに追加
git add .
# 変更内容を要約したメッセージと共にコミット
git commit -m "feat: Initialize dbt project with DuckDB connection"
# 作成したブランチをリモートリポジトリにプッシュ
git push origin feat/initial-dbt-setupGitHubのWebサイトにアクセスすると、今プッシュしたブランチからプルリクエスト(PR)を作成するための通知が表示されているはずです。その通知から、mainブランチへのプルリクエストを作成してください。これにより、実際のチーム開発におけるコードレビューとマージのフローを疑似体験できます。
これで、あなたのローカル環境構築の成果がGitHub上に安全に記録されました。いつでもこの状態から作業を再開できますね。
まとめと次のステップ
お疲れ様でした!この記事を通して、あなたは以下の重要なステップをすべて独力で達成しました。
- GitHubリポジトリを作成し、ローカルにクローンしました。
- プロジェクト専用のPython仮想環境を構築しました。
- dbt CoreとDuckDBアダプタをインストールしました。
dbt initでdbtプロジェクトを初期化し、profiles.ymlでDuckDBへの接続設定を行いました。dbt runで最初のモデルを実行し、データベースにオブジェクトが作成されることを確認しました。- すべての成果をGitでコミットし、GitHubにプッシュしました。
これであなたは、dbtを使ったモダンなデータモデリングの確かな第一歩を踏み出しました。次回からは、jaffle_shopという架空のEコマースサイトのサンプルデータセットを使って、より実践的なデータモデリングに挑戦します。具体的には、seeds機能でのデータロード、ソースデータを整形するステージングモデルの作成、そしてdbtの強力な機能であるref関数を活用したモデル間の依存関係の構築などを学んでいきます。
最初は覚えることが多いと感じるかもしれませんが、一つひとつのステップは非常にシンプルです。今回構築したこの環境をベースに、データ変換の楽しさとdbtのパワーをさらに深く探求していきましょう。次回も一緒に学んでいけることを楽しみにしています!