
こんにちは、六本木アナリティクスエンジニアのTaku(@aelabdata )です。
dbt入門の第11回です。前回は、データモデルの意図を明確にする「ドキュメンテーション」の重要性について解説しました。
今回は、データパイプラインの信頼性を確保するための、次の重要なステップである「テスト」に焦点を当てます。
テストは、構築したモデルが期待通りのデータを生成しているかを確認し、データ品質を保証するための不可欠なプロセスです。信頼性の高いデータパイプラインを構築し、ビジネスサイドのステークホルダーからの信頼を得るためには、テストの実装が鍵となります。
この記事では、dbtにおけるテストの基本から具体的な実装方法まで、初心者の方でも安心して進められるように、一歩一歩、解説していきます。
dbtにおけるテストとは?
テストは構築したデータモデルが期待通りに動作し、ビジネス上の意思決定に利用できる品質を担保するための「セーフティネット」です。
コードを実行してエラーが出なければそれで終わり、ではありません。データの「中身」が本当に正しいのかを継続的に検証する仕組みこそが、データパイプライン全体の信頼性を支えるのです。
dbtにおけるテストの重要性は、以下の3つの側面に集約されます。
- データの信頼性向上 テストは、データモデルから生成されるデータの正確性を保証します。例えば、「顧客IDは必ずユニークであるべき」「注文ステータスは定義された値以外は入らない」といったルールを自動で検証することで、下流のダッシュボードや分析で使われるデータの品質を担保します。これにより、データ利用者からの「この数値、本当に合ってる?」といった疑問を減らし、データチームへの信頼を構築します。
- 開発プロセスの効率化 「
dbt runは成功したのに、BIツールで見たらデータがおかしい…」といった経験はありませんか?テストを導入すれば、このような事態を防ぎ、データの問題を開発サイクルの早い段階で発見できます。問題の発見が早ければ早いほど、原因究明や修正にかかるコストは小さくなり、手戻りを減らして開発サイクル全体を加速させることができます。 - コラボレーションの円滑化 チームで開発を進める上で、テストは非常に重要な役割を果たします。各データモデルが「守るべき品質基準」をコードとして明確に定義することで、他のメンバーがそのモデルを安心して利用したり、改修したりできます。これにより、口頭での確認や属人化を防ぎ、プロジェクト全体の保守性を飛躍的に高めることができます。
dbtには、目的別にいくつかのテストが用意されています。ここでは主要な3つの種類を紹介します。
- データテスト (Data Test) モデルがデータウェアハウス上にマテリアライズ(実体化)された後に、その結果データに対して実行されるテストです。データの整合性やビジネスルールへの準拠を検証します。
- ユニットテスト (Unit Test) モデルをマテリアライズする前に、モデル内のSQL変換ロジックそのものを検証するテストです。静的な入力データ(モックデータ)を用いて、複雑な
CASE文やウィンドウ関数などが期待通りに動作するかを個別に確認できます。 - ソース鮮度テスト (Source Freshness) ELTパイプラインの起点となるソースデータが、どれだけ最新の状態に保たれているかを確認するためのテストです。「最終ロードからX時間以上経過している場合は警告する」といったルールを定義し、データの鮮度を監視します。
初学者が最初に学ぶべき最も一般的なテストが「データテスト」です。データテストには、Generic Data TestとSingular Data Testがあります。
Generic Data Test
dbtには、すぐに利用できる4つの汎用的なデータテスト(Generic Data Test)が組み込まれています。これらはYAMLファイル内で簡単に設定でき、多くのデータ品質チェックをカバーします。
| テスト名 | 説明 | ユースケース例 |
|---|---|---|
unique | 指定した列の値が一意であることを検証します。 | customer_idやorder_idなどの主キー列 |
not_null | 指定した列にNULL値が含まれていないことを検証します。 | 主キー列や、分析上必須となる重要な列 |
accepted_values | 指定した列の値が、提供されたリスト内の値のいずれかであることを検証します。 | sku列が['BEV-001', 'BEV-002', ...]のいずれかであること |
relationships | ある列の値が、別のモデルの特定の列に存在することを検証します(参照整合性)。 | ordersテーブルのcustomer_idが、customersテーブルのidに存在すること |
これらのテストは、SQLで「表明に反するレコードを探す」クエリとして実行されます。例えばuniqueテストは重複する値を探し、not_nullテストはNULL値を探します。クエリ結果が0件であれば、テストは「成功(PASS)」と判断されます。
Singular Data tests
Singular tests(単体テストとも呼ばれます)は、Generic testsでは表現できない、より複雑なビジネスロジックを検証するために使用します。このテストは、独立したSQLファイルとして記述します。テスト用のSQLクエリが1行でも結果を返した場合に「失敗」と見なされる、という仕組みです。
SQLで自由にロジックを記述できるため、非常に高い柔軟性を持ちます。例えば、「特定の条件下で、あるカラムの値は別のカラムの値より必ず大きくなければならない」といった、複数のカラムやテーブルにまたがる複雑な条件を検証したい場合に、Singular testが活躍します。
では、これらの概念を実際にどのようにコードに落とし込み、プロジェクトに適用していくのか、次のセクションで実践してみましょう。
実践:dbtのデータテストを実装してみよう!
ここからは、実際に手を動かしてテストを実装していきます。一つ一つのステップを丁寧に解説しますので、難しく考える必要はありません。一緒に頑張りましょう!
今回は、StagingモデルにGeneric testsを追加してみましょう。 models/staging/jaffle_shop/_jaffle_shop.ymlファイルを開き、以下の内容を追記してください。
version: 2
models:
- name: stg_jaffle_shop__raw_orders
columns:
- name: order_id
data_tests:
- unique
- not_null
- name: customer_id
data_tests:
- relationships:
to: ref('stg_jaffle_shop__raw_customers')
field: customer_id
...
- name: stg_jaffle_shop__raw_customers
columns:
- name: customer_id
data_tests:
- unique
- not_null
...
- name: stg_jaffle_shop__raw_items
columns:
- name: item_id
data_tests:
- unique
- not_null
- name: order_id
data_tests:
- relationships:
to: ref('stg_jaffle_shop__raw_orders')
field: order_id
- name: sku
data_tests:
- accepted_values:
values: [BEV-001, BEV-002, BEV-003, BEV-004, BEV-005,
JAF-001, JAF-002, JAF-003, JAF-004, JAF-005]
...このコードが何を検証しているのか、具体的に見ていきましょう。
stg_jaffle_shop__raw_ordersのorder_id:uniqueとnot_nullの2つのテストを適用することで、この列が重複なく、かつ欠損なく一意に識別する「主キー」としての役割を果たすことを保証しています。これはデータモデリングの基本であり、最も重要なテストの一つです。stg_jaffle_shop__raw_ordersのcustomer_id:relationshipsテストは非常に強力です。ここでは、「stg_jaffle_shop__raw_ordersテーブルのすべてのcustomer_idは、必ずstg_jaffle_shop__raw_customerテーブルのcustomer_idとして存在している」という参照整合性を保証しています。これにより、「存在しない顧客からの注文」といったデータの矛盾が発生するのを防ぐことができます。stg_jaffle_shop__raw_itemsのsku:accepted_valuesテストにより、商品コードが'BEC-001','BEV-002', …,'JAF-004','JAF-005'のいずれかの値しか取らないことを保証します。これにより、予期せぬ値がデータに混入することを防ぎ、データの一貫性を保ちます。
次に、Singular testを実装します。ここでは、「注文データ(orders)において、注文金額(order_total)がマイナスになることはあり得ない」というビジネスルールを検証するシナリオで進めましょう。
まず、プロジェクトのルートディレクトリにtestsという名前のディレクトリを新規作成します。次に、testsディレクトリの中にassert_positive_total_for_orders.sqlという名前で新しいSQLファイルを作成します。
作成したファイルに、以下のSQLコードを記述してください。
select
order_id,
order_total
from {{ ref("stg_jaffle_shop__raw_orders") }}
where order_total < 0このSQLクエリがどのように機能するのかを解説します。このクエリは、stg_jaffle_shop__raw_ordersモデルからorder_total(注文金額)が0未満のレコードを探します。もし1件でも該当するレコードがあれば、その行がクエリ結果として返され、dbtはテストを失敗と判断します。該当するレコードが1件もなければ、クエリは0行を返し、テストは成功となります。
実装したテストを実行してみましょう。
プロジェクトに定義された全てのテストを実行するには、ターミナルで以下のコマンドを実行します。
dbt testすべてのテストが成功すると、ターミナルには各テストがPASSしたことを示す出力が表示されます。
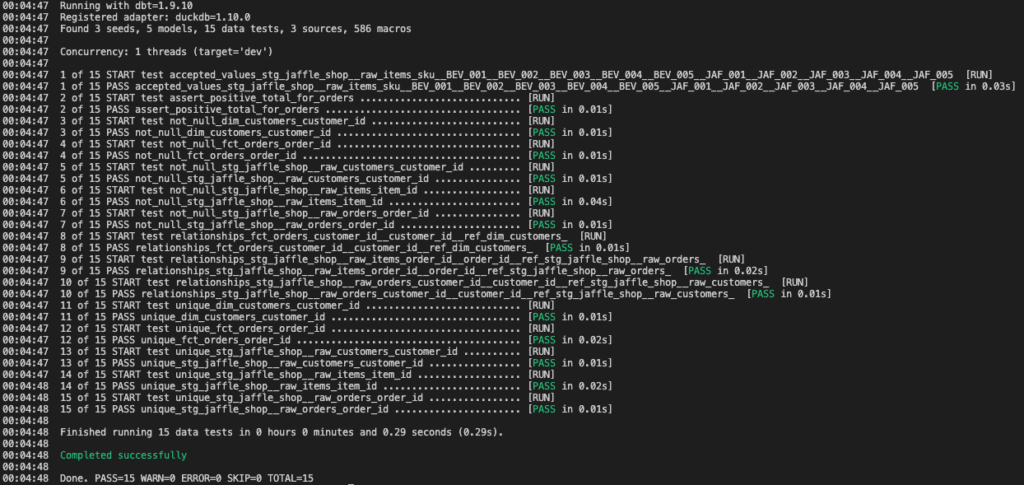
特定のモデルに関連するテストだけを実行したい場合もあります。例えば、stg_jaffle_shop__raw_ordersモデルのテストだけを実行するには、--selectフラグを使います。これは、大規模なプロジェクトで変更箇所だけを効率的にテストしたい場合に非常に便利です。
これで、dbtの主要なテスト機能を一通り実装し、実行することができました。
まとめ
この記事では、dbtにおける「テスト」の概念から具体的な実装方法までを解説しました。テストは、データパイプラインの品質と信頼性を担保するための、重要な活動です。
最後に、この記事のポイントを振り返りましょう。
- テストは信頼の礎: データモデルの品質をコードで保証することは、データ利用者が安心して分析できる環境を構築するために不可欠です。テストは、データに対する信頼そのものを支える土台となります。
- 2種類のテストを使い分ける:
*.ymlで簡単に定義できる「Generic tests」で普遍的なデータ品質(一意性、非NULLなど)を網羅的に確保し、tests/*.sqlで記述する「Singular tests」でプロジェクト固有の複雑なビジネスルール(例:注文金額がマイナスでないこと)をピンポイントで検証する。 - テストは習慣化が重要: モデルを開発・修正する際には、必ずテストも一緒に実装する習慣をつけましょう。この小さな積み重ねが、長期的に見てプロジェクトの健全性を保ち、将来の自分やチームを助けることになります。
この記事をもって、dbt入門講座は一区切りとなります。これまでに学んだモデリング、ドキュメンテーション、そして今回のテストは、信頼性の高いデータ基盤を構築するアナリティクスエンジニアとしての不可欠なスキルセットです。
dbtの世界は奥深く、まだまだ探求すべき機能やベストプラクティスがたくさんあります。これからも、講座記事を作成して発信していきますので、よろしくお願いします!
