
こんにちは、六本木アナリティクスエンジニアのTaku(@aelabdata )です。
dbt入門の第5回です。前回は、dbt seedコマンドを使い、jaffle_shopのサンプルデータをローカルのDuckDBにロードできました。
今回は、データモデリングする前の準備段階として、成功するdbtプロジェクトの設計思想に焦点を当てた「理論編」です。
なぜdbtプロジェクトに「構造」が重要なのかを解説し、dbt Labsが推奨する具体的な3層構造(Staging, Intermediate, Marts)と、最終的なアウトプットを分析に適した形に整えるためのディメンショナルモデリングについて解説します。
なぜdbtプロジェクトに「構造」が重要なのか?
dbt Labsのベストプラクティスガイド How we structure our dbt projects の冒頭を日本語に訳して、本質を抜粋します。
アナリティクスエンジニアリング(AE)の本質は、人が協力してより良い意思決定を大規模に行えるよう支援することです。私たちには意思決定能力の限界があり、他者とのコラボレーションを最適化するためにシステムやパターンに依存しています。
この特性から、共同プロジェクトにおいては、一貫性があり分かりやすい規範(ルール)を確立することが不可欠です。そうすることで、チームの限られた意思決定能力を、「フォルダの配置場所やファイル名」といった瑣末な問題ではなく、本質的なビジネス課題の解決に集中させることができます。
なぜdbtプロジェクトに「構造」が重要なのかは、以下の3点に集約されます。
- AEの本質: より良い意思決定を大規模に行えるように支援すること。
- 協調開発: 共同プロジェクトでは、一貫性があり分かりやすい規範の確立が不可欠。
- 集中力の最大化: チームの限られた意思決定能力を、本質的な課題解決に集中させる。
dbtプロジェクトが目指すプロセスは、データが外部システムに依存した「ソース準拠(Source-conformed)」の状態から、ビジネスニーズや組織独自の定義に合わせて整形された「ビジネス準拠(Business-conformed)」の状態へと移行することです。
この「ソース準拠」から「ビジネス準拠」への移行を、体系的かつ効率的に実現するための具体的な設計思想として、dbt Labsが推奨するプロジェクト構造が存在します。次のセクションでは、その具体的な3層構造について詳しく見ていきましょう。
dbtプロジェクトの3層構造
dbtプロジェクトの変換フローを論理的かつモジュール化された形で整理するために、dbt LabsではStaging(ステージング)、Intermediate(中間)、Marts(マート)の3つの層からなる構造を推奨しています。
 【日本語解説】dbtベストプラクティス:成功するプロジェクト構造
【日本語解説】dbtベストプラクティス:成功するプロジェクト構造
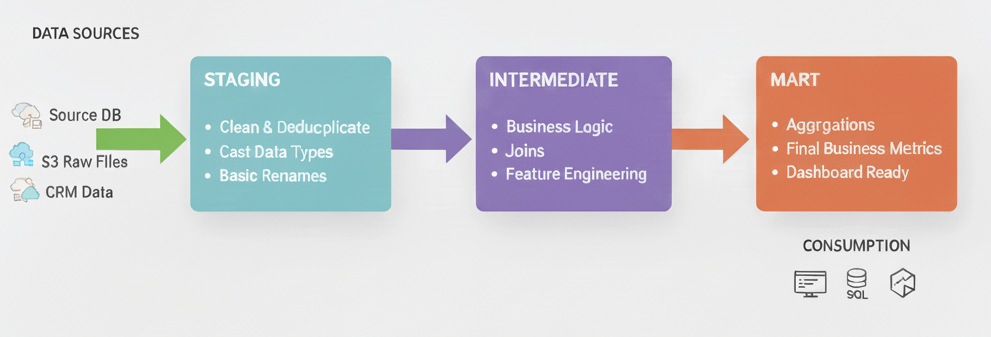
この構造は、データがソースシステムから取り込まれ、段階的にクリーンアップ、変換、集約され、最終的にビジネスユーザーが利用しやすい形へと整形されていく流れを明確にします。各層は明確な役割を持ち、パイプライン全体の可読性、再利用性、そしてメンテナンス性を高めることに貢献します。
以下に、各層の役割と目的をまとめます。
ステージング層は、ソースデータに最小限の処理を施し、プロジェクト全体の信頼できる基盤を構築します。
- 目的: ソースシステムの癖を抽象化し、プロジェクトの他の部分が信頼して利用できる、標準化されたデータを作成します。
- 処理の原則: 原子的な構成要素(Atoms)を作成する層であり、結合(JOIN)は行いません。ソーステーブルと1対1の関係を保ちます。
- 具体的な変換(最小限):
- カラム名の変更(例:
id→customer_idなど、プロジェクトの命名規則に統一) - データ型のキャスト(型変換)
- 基本的なデータのクリーンアップ(NULL値の標準化など)
- カラム名の変更(例:
Intermediate層は、Staging層のデータを基に、Marts層の構築に必要な複雑なビジネスロジックや共通処理を集約・カプセル化します。
- 目的: 最終的なMartsモデルをシンプルに保つため、複雑なロジックを段階的に適用・モジュール化(部品化)します。
- 処理の原則:
- 複数のStagingモデルの結合(JOIN)を行います。
- 複雑なビジネスロジックを適用し、意味のある中間データを作成します。
- 活用メリット:
- 再利用性の向上: 複数のMartsモデルで共通して利用される変換処理をカプセル化します。
- 保守性の向上: 複雑な処理がこの層に集約されるため、ロジックの変更が必要な際の影響範囲を限定できます。
- 可読性の向上: Marts層のSQLをシンプルに保つことができます。
Mart層は、中間層で整備されたデータを組み合わせ、ビジネス部門が直接利用するための最終的なデータセットを構築します。
- 目的:
- ビジネス部門が直接利用できる、最終的なデータマートを作成します。
- BIツール(Tableau, Lookerなど)からの参照に最適化されたデータを提供します。
- 処理の原則:
- ディメンショナルモデリング(次章で解説)を実践します。
- 中間モデルを組み合わせて、ビジネスで定義されたエンティティ(顧客、注文など)に関する「広く、リッチなビジョン」を持つモデルを構築します。
- 特徴:
- 利用者の信頼性: ビジネスロジックが最終的に確定し、品質が保証されたデータ資産となります。
- 高い分析効率: スター・スキーマにより、BIツールでのクエリパフォーマンスと操作性が向上します。
この3層構造は、いわばデータを組み立てるためのワークフローアーキテクチャです。これにより、データパイプラインは論理的に整理され、各変換ステップの役割が明確になり、再利用性の高い「部品」が作られます。
では、この部品を使って最終的にどのようなデータアーキテクチャを構築すべきでしょうか?その答えが、Marts層で実践するディメンショナルモデリングです。
分析のためのデータ設計:ディメンショナルモデリング入門
Marts層で作成する「ビジネス準拠」のデータモデルを、具体的にどのように設計すればよいのでしょうか。
この問いに対する強力な答えの一つが、数十年にわたりデータウェアハウスの世界で実績を積んできた「ディメンショナルモデリング」という設計手法です。このアプローチの目的は、分析クエリのパフォーマンスを最大化し、ビジネスユーザーがデータの構造を直感的に理解できるようにすることです。
ディメンショナルモデリングは、主に2種類のテーブルから構成されます。
- ビジネスプロセスの中で発生したイベントや測定可能な数値を記録するテーブルです。
- 例えば、「注文履歴」や「支払い記録」などがこれに該当します。
- ファクトテーブルには、いつ、どこで、何が起こったかを示す指標(例:売上金額、注文数)と、各ディメンションへの外部キーが含まれます。
- ファクト(事実)を説明するための文脈情報や属性を保持するテーブルです。
- 「誰が」「何を」「どこで」といった情報を提供します。
- 例えば、「顧客マスタ」「商品マスタ」「店舗情報」などが該当します。
- 顧客の氏名や住所、商品のカテゴリや価格といった、分析の切り口となる属性情報が格納されます。
これら2種類のテーブルを組み合わせた構造は、中心にファクトテーブルを置き、そこから放射状にディメンションテーブルが繋がるように見えることから「スター・スキーマ」と呼ばれます。この構造は、複雑なJOINを減らし、集計クエリを高速に実行できるため、分析用途に非常に適しています。
このスター・スキーマこそが、Staging層とIntermediate層で準備した部品を組み立てて完成させる、ビジネスが求める最終的な設計図なのです。
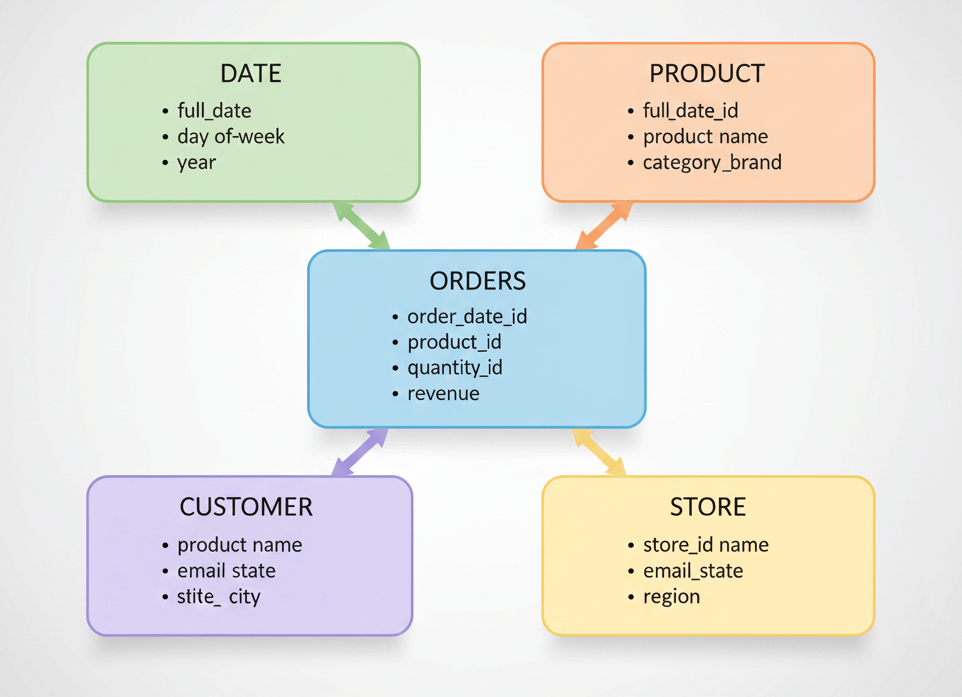
結論として、Marts層の目的である「ビジネスで定義されたエンティティを作成する」ことは、多くの場合、このスター・スキーマを構築することに相当します。
dbtの3層構造を経て整形されたデータは、このディメンショナルモデリングという設計指針を通じて、最終的にビジネスにとって価値のある、分析しやすい形のアウトプットとなるのです。
まとめと次のステップ
この記事では、成功するdbtプロジェクトを構築するための2つの重要な概念、「3層構造」と「ディメンショナルモデリング」について解説しました。
これらのプラクティスは、単なるルールではなく、複雑なデータパイプラインを長期的に維持・発展させていくための強力な羅針盤となります。これらの原則に従うことで、以下のようなメリットが得られます。
- データのリネージ(系統)の明確化: データの流れが
Staging -> Intermediate -> Martsという一貫したパスを辿るため、追跡が非常に容易になります。 - メンテナンス性の向上: 各モデルの役割が明確であるため、ロジックの変更やデバッグが必要な際に、影響範囲を特定しやすくなります。
- スケーラビリティの確保: プロジェクトの規模が拡大し、モデルや参加する開発者の数が増えても、確立された構造が秩序を保ち、破綻を防ぎます。
今回は、dbtプロジェクト設計の理論編でした。ここで学んだ概念は、あなたのdbtプロジェクトを次のレベルへと引き上げるための基礎となります。
次はいよいよ実践です。次回は、今回学んだ概念を具体的なコードに落とし込むために、Jaffle Shopのサンプルプロジェクトを使ったハンズオンを行いますので、ぜひご期待ください。
本講座で扱うデータ変換処理は比較的シンプルであり、ステージングモデル同士を直接結合してもSQLが複雑になりすぎることはありません。そのため、学習のしやすさと構成のシンプルさを優先し、今回はIntermediate層を省略して、Staging層から直接Marts層を作成するアプローチを採用します。

